원래 corner detect를 찾아보다가 sift, harris 알고리즘 같은걸 보고 이 알고리즘 들은 table detect에 활용이 잘 안돼서 아에 box detect 하는 방법을 찾게되었다.
이 글은 기록용..
아래 사진에서 표 부분만 좌표를 구할 것이다

필요 Library
import cv2
import numpy as np
Image Binaray
gray_scale=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
_,img_bin = cv2.threshold(gray_scale,150,225,cv2.THRESH_BINARY)
img_bin=~img_bin표에 컬러가 있을 수 있으니 먼저 gray_scale로 변환하고, 이진화시킴
이진화된 이미지를 반전(~) 시켜주면 아래와 같은 상태가 된다

탐색할 Line 크기 설정 및 커널화
### selecting min size as 15 pixels
line_min_width = 15
kernal_h = np.ones((1,line_min_width), np.uint8)
kernal_v = np.ones((line_min_width,1), np.uint8)탐색할 표의 선 굵기를 설정한다 보면 될듯 하다.
만든 커널로 수평(h), 수직(v) 추출 후 MIX
# Horizontal Kernel, Vertical Kernel
img_bin_h = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, kernal_h)
img_bin_v = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, kernal_v)
# MIX Kernel
img_bin_final=img_bin_h|img_bin_v가로선과 세로선만 추출 후 합치면 아래와 같은 결과가 나온다.

인식하기 쉽도록 3x3 크기의 1로 채워진 매트릭스 생성 (dilate를 하기 위해서)
final_kernel = np.ones((3,3), np.uint8)
img_bin_final=cv2.dilate(img_bin_final, final_kernel, iterations=1)
cv.connectedComponentsWithStats
_, labels, stats,_ = cv2.connectedComponentsWithStats(~img_bin_final, connectivity=8, ltype=cv2.CV_32S)
n1 = np.array(stats[2:])cv2.connectedComponentsWithStats(image, labels=None, stats=None, centroids=None, connectivity=None, ltype=None) -> retval, labels, stats, centroids
• image: 8비트 1채널 영상
• labels: 레이블 맵 행렬. 입력 영상과 같은 크기. numpy.ndarray.
• stats: 각 객체의 바운딩 박스, 픽셀 개수 정보를 담은 행렬. numpy.ndarray. shape=(N, 5), dtype=numpy.int32.
• centroids: 각 객체의 무게 중심 위치 정보를 담은 행렬 numpy.ndarray. shape=(N, 2), dtype=numpy.float64.
• ltype: labels 행렬 타입. cv2.CV_32S 또는 cv2.CV_16S. 기본값은 cv2.CV_32S
여기서 사용할건 stats
이 안에 검출한 객체의 좌표값이 들어있다. [x, y, w, h, pixel]
사실 여기서 단순하게 검출한 모든 box를 그려줄 수 있지만 나는 일단 표 자체만 뽑고싶기 때문에 약간의 전처리가 필요했다
단순하게 모든 box 그리는 코드
for x,y,w,h,area in stats[2:]:
# print(f"x: {x}, y: {y}, w: {w}, h: {h}, pixel: {area}, x+w: {x+w}, y+h: {y+h}")
cv2.rectangle(image,(x,y), (x+w, y+h),(0,255,0), 2)
전체 표만 그리는 코드
xw = n1[:, [0,2]].sum(axis=1).max()
yh = n1[:, [1,3]].sum(axis=1).max()
cv2.rectangle(image,(min_x, min_y),(xw, yh),(0,0,255), 2)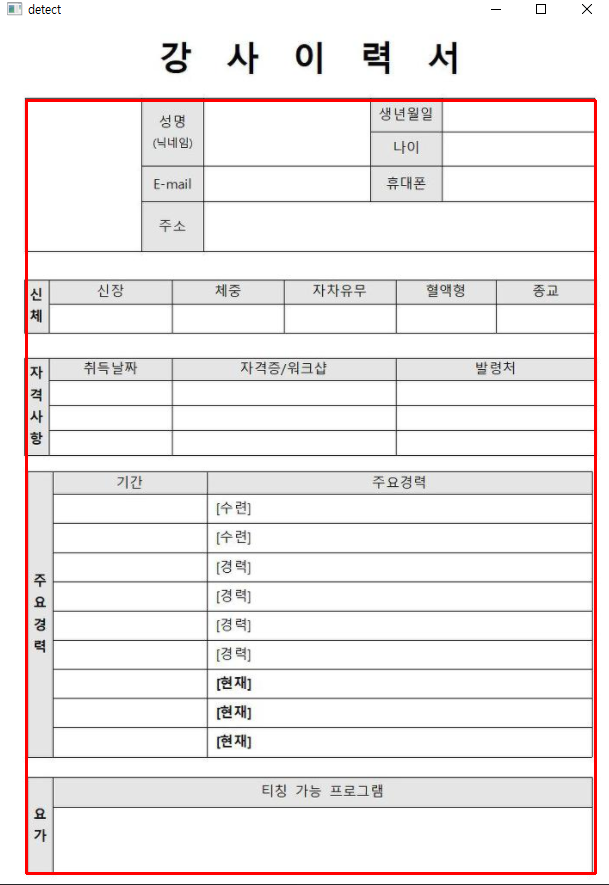
전체 표 인식에서 x 좌표와 y좌표의 시작부분은 인식된 box의 최소값으로 했고
끝 부분은 x+w의 최대값과 y+h의 최대값을 각각 구해서 넣어주었다.
그리기
cv2.imshow('detect', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
끝
ref: https://towardsdatascience.com/checkbox-table-cell-detection-using-opencv-python-332c57d25171
'공부 > Python' 카테고리의 다른 글
| [python] 클래스를 함수처럼 사용할수 있게.. __call__함수 (0) | 2021.06.15 |
|---|---|
| [Python] @Decorator 파이썬 @데코레이터 (2) | 2021.06.11 |
| [python] 파이썬에서의 json(str)과 dictionary 타입.. 그리고 request (0) | 2021.05.27 |
| [python] 문자열을 변수로 사용하고 싶을때 eval() (1) | 2021.05.14 |
| [python] PDF에서 Text 추출하기 (Extract elements from a PDF using Python) (0) | 2021.03.10 |
댓글