회사에서 사용하는 GPU Server가 한대 있는데, 두명이서 같이 쓰다보니 환경설정이 꼬일때가 많다.
가상환경도 쓰고 Docker도 쓰지만, 상대방이 이것저것 설치하다보면 내 환경과 충돌나는 경우가 무조건 있기마련...
DeepLearning을 학습 할 일이 있어서 torch를 새로 설치하고 이것저것 설정을 만진김에 한번에 정리 겸 포스팅..
내 환경
# result check.py
PyTorch version: 1.7.1+cu110
Is debug build: False
CUDA used to build PyTorch: 11.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.8.0-59-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 10.1.243
GPU models and configuration: GPU 0: GeForce RTX 3090
Nvidia driver version: 460.91.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.2
[pip3] pytorch-lightning==1.3.8
[pip3] torch==1.7.1+cu110
[pip3] torchaudio==0.7.2
[pip3] torchmetrics==0.5.1
[pip3] torchvision==0.8.2+cu110
[conda] Could not collect
첫번째 문제
nvidia-smi 명령어 입력 시 Error 발생
Failed to initialize NVML: Driver/library version mismatch해결방법
nvidia driver를 unload 하고 관련 모듈을 삭제하면 된다.
nvidia와 관련된 사용중인 driver 목록
# lsmod | grep nvidia
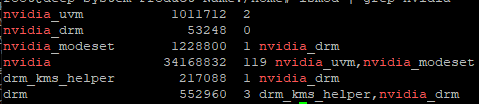
사용중인 nvidia driver를 모두 unload
# rmmod nvidia_uvm nvidia_drm nvidia_modeset
이때, 혹시 "rmmod: ERROR: Module nvidia is in use" 오류가 뜨면 프로세스가 실행중인 것 이므로 관련 프로세스를 검색하여 PID KILL해줌
# lsof /dev/nvidia*
# kill [PID]
# rmmod nvidia
확인해보면 아무것도 뜨지않아야 정상이다.
# lsmod | grep nvidia
결과
# nvidia-smi
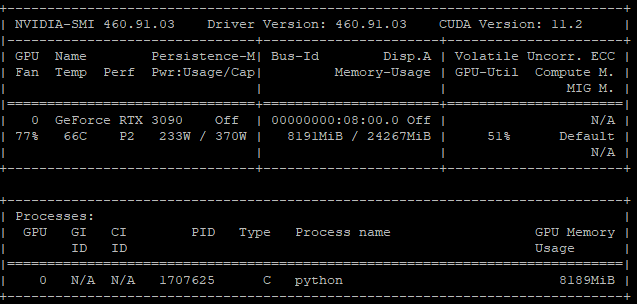
두번째 문제
pytorch로 학습 실행시 cuda version error 발생
CUDA error: no kernel image is available for execution on the device
nvidia-msi 명령어와 nvcc -V 명령어로 확인해보면 CUDA Version은 11.2로 RTX 3090에 알맞게 잘 설치가 되어있으나
python 내부의 torch는 cuda 10을 사용하게 되면서 에러가 발생했다.
torch 라이브러리를 import해서 확인해 볼 수 있다.
import torch
torch.version.cuda
해결방법
베이스 운영체제에 cuda11이 정상적으로 잘 설치 되었다는 가정 하에 해결방법은 간단하다
pytorch를 재설치 해주면 됨.
일단 기존의 torch를 제거해준다.
# pip uninstall torch
그리고 원하는 버전의 torch를 설치해 줘야 하는데, 꼭! cuda 버전에 알맞게 설치해줘야한다!
나는 이 부분에서 단순히 pip install torch==version 이런식으로 설치를 해서 계속 같은 오류가 발생했었다..
사용하고자하는 pytorch 버전에 따라, 그리고 cuda 버전에 따라 설치 스크립트가 달라지게 되므로 꼭 pytorch 공식홈페이지에서 알맞는 버전을 찾아서 다운로드하길 바란다..
내 경우에는 torch 1.7.1 버전과 cuda11 이 필요했기 때문에 아래와 같이 설치해주었다.
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
이제 학습이 잘 돌아간다..!
pytorch 홈페이지 주소
https://pytorch.org/get-started/previous-versions/
ref.
https://jangjy.tistory.com/300
'의지박약 > DevOps' 카테고리의 다른 글
| [Airflow] 기본 DB를 Postgresql로 변경하기 (1) | 2021.09.15 |
|---|---|
| [AirFlow] db init ERROR - Fail to ~ GET /api/v1/connections ... AttributeError: columns (0) | 2021.09.15 |
| [Shell Script] .env 파일 읽어오기 (0) | 2021.09.14 |
| [Shell Script] 쉘 스크립트에서 config.ini 파일 읽고 쓰기 (feat. konfig) (0) | 2021.09.08 |
| [Docker] Docker run 상태 유지하기 (0) | 2021.09.01 |




댓글