Gradient Descent - 경사하강법
딥 러닝에서는 함수의 예측값과 실제값의 차이(오류)를 줄이는 방향으로 가중치(w)를 계속 조절해야 하는데, 대표적인 방법으로 경사하강법을 사용한다.
핵심은 가중치(w)를 계속 조절하다가 더이상 오류값이 좁혀지지 않으면 그때가 최적이라 판단하고 w를 반환해 주는것이다.
그럼 어떻게..?
gradient descent는 함수의 기울기를 이용해 최소값을 알아보는데 이 방법으로 알수있는것은 아래와 같다.
1. 기울기가 양수인 경우: x값이 커질 수록 함수 값이 커짐 => x를 음의 방향으로 옮겨!
- 기울기가 음수인 경우: x값이 커질 수록 함수 값이 작아짐 => x를 양의 방향으로 옮겨!
2. 기울기의 값이 큰 경우(상대적으로): x의 위치가 최소값/최대값에 해당되는 x좌표로부터 멀리 떨어져 있음
=> 현재 x의 값이 극소값에서 멀 때는 많이 이동, 가까우면 조금이동 => step
MSE Cost Function(Loss Function)
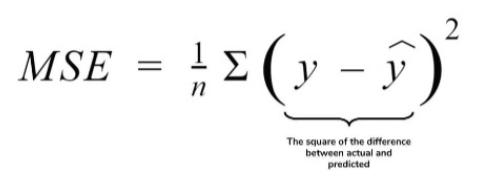
위 식은 일반적인 MSE 방법이고,
아래는 MSE를 Deep Learning에 활용하기 위해 풀어서 작성한 것이다.
MSE - Cost
w - 회귀 계수
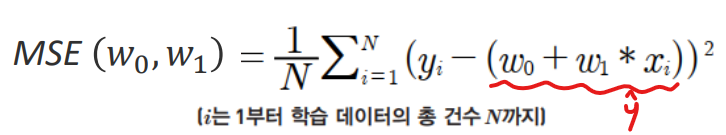
위 비용함수가 반환하는 값(오류값)을 더 이상 감소하지 않을때까지 감소시켜 값을 구함 = loss function
MSE Loss함수는 변수가 w 파라미터이다.
위 식을 미분하여(기울기) 최소값을 구해야 하는데 w0와 w1각각을 풀어서 계산(편미분)해 줘야한다.
위 식을 또 풀어보면

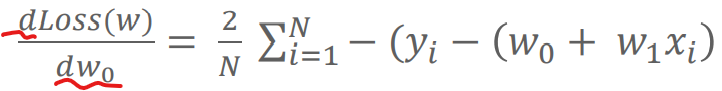
이렇게 표현할 수 있다.
Update Weight(w1), Bias(w0)
w는 loss function의 편미분 값을 update하면서 계속해서 갱신해야한다.
여기서 학습률(leraning rate)이라는 개념이 나오는데, update는 기존 w값에 loss function 미분값을 감소 시키는(Gradient Decent)방법을 사용하는 것이다.
그냥 단순히 랜덤으로 감소시키는 것이 아니라 일정한 계수를 곱해서 감소시키는데 이 일정한 계수가 바로 학습률이다.

구현
def y(feat, weight):
return feat * weight
def mse_loss(y, target):
return np.mean((target - y)**2)
def gradient(weight, feat, target):
return 2 * feat * ( y(feat, weight) - target)
def delta_weight(w_k, feat, target, learning_rate):
return learning_rate * np.mean(gradient(w_k, feat, target))
아직 미완.. 작성중
'공부 > AI' 카테고리의 다른 글
| [DL] TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]] (0) | 2021.09.29 |
|---|---|
| [DL]활성화 함수 (Activation Function) 개념 (0) | 2021.06.22 |
| [DL기초] batch_size, epoch, step 개념 그리고 iteration (1) | 2021.06.09 |
| [DeepLearning] 딥러닝의 전체적인 흐름..? (0) | 2021.03.08 |


댓글