Deep Learning, Machine Leraning을 공부하다보면 여러 Layer를 구성하고 항상 마지막 출력값에 적용해주는 함수가 있다.
개념을 알지 못하고 단순히 코드필사만 해본 사람이라도 한번쯤은 봤을법 한, 그 함수들..
Sigmoid, ReLU 등등..
이러한 함수들이 바로 Activation Function 이다.
아래 설명은 https://playground.tensorflow.org/ 을 활용한다.
정의
입력 신호의 총합을 출력신호로 변환하는 함수를 일반적으로 Activation Function이라고 한다.
Actication Function의 목적
간단하게 말하면 Deep Learning Network에 비선형성을 적용하기 위함이다.
처음엔 나도 그냥 이게 뭐? 비선형성이 적용되는게 뭔데? 이렇게 생각했지만.. 그림으로 보면 간단하다.
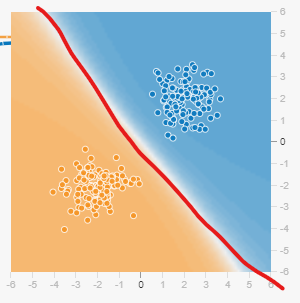

두 그림 모두 간단한 이진분류의 예시이다.
왼쪽 그림은 (직)선형으로 판별 기준이 제공된 그림이이고, 오른쪽그림은 나름 비선형으로 판별기준이 적용된 그림이다.
만약 선형 활성화 함수를 이용해서 오른쪽 그림을 분류하고자 한다면 어떻게 해야할까?
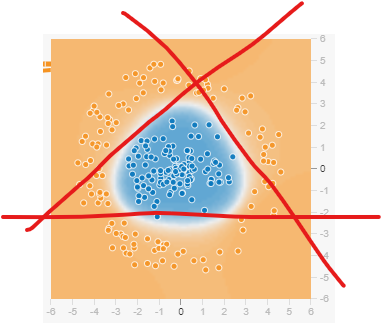
아무리 분류하려고 해도 직선으로는 한계가 있다..
저 선 한개 한개가 선형 Activation Function을 적용하여 분류하려고 노력한 거라 생각하면 된다.
하지만 비선형 Activation function을 사용하면 아주 동그랗고 예쁘게 분류가 가능하다....!
Activation Function 종류와 역할
일반적인 DeepLearning Layer 구조이다. playground tensorflow 최고야
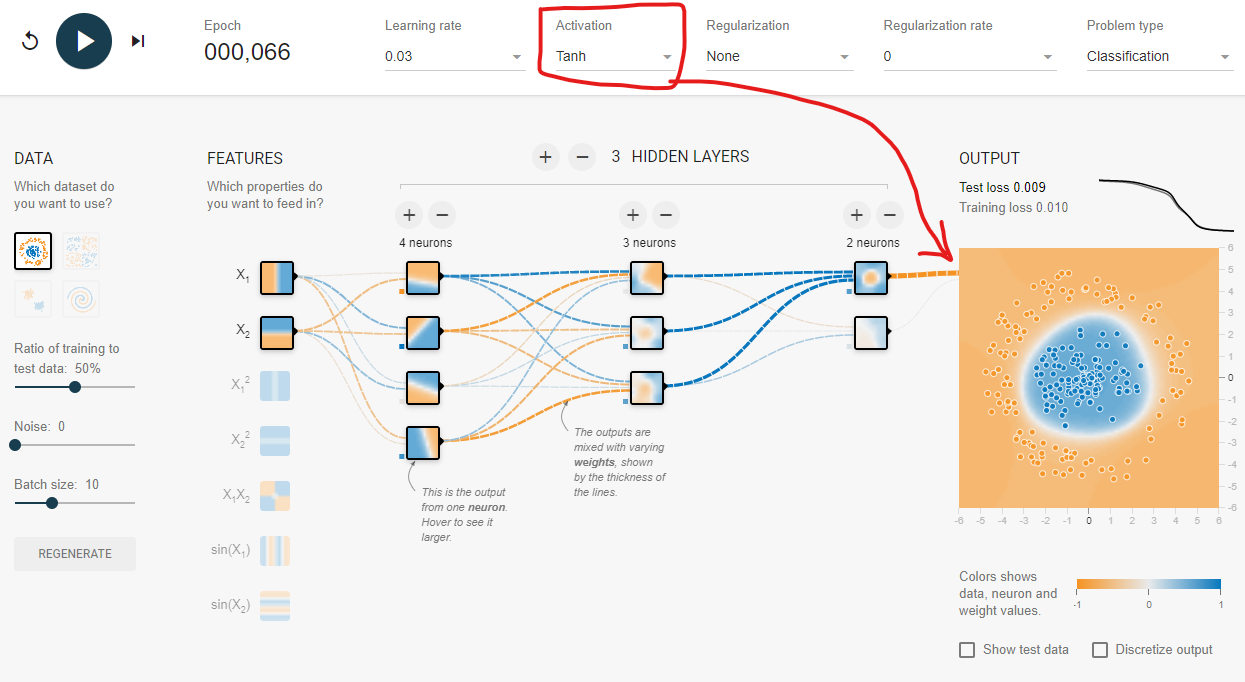
위 그림을 보면 Hidden Layer 이후 가장 마지막 Output Layer가 생략되었는데 이 Output Layer에서 Activation Function이 적용된다고 보면 된다. (ReLU 계열은 Hidden Layer에서 사용됨. 뒤에 설명)
다음으로는 일반적으로 자주 쓰이는 Activation Function에 대해 알아본다.
cs231n 강의에서는 6가지 정도의 함수를 설명했지만, 나는 자주 쓰이는 3가지 함수에 대해서만 설명하고자 한다.
playground tensorflow에서도 대표적인 Activation만 다루고 있다! (Linear는 제외..ㅎ)
간단하게 세가지의 활성화 함수와 사용 용도이다.
1. Sigmoid
이진 분류(Binary Classification)시 마지막 출력층에서 사용되는 함수

이 함수는 일반적으로 Output Layer에서 주로 사용되는데, Vanishing Gradient 문제가 있기 때문에 Hidden Layer에서는 사용이 어렵다.
간단하게 말하면 위 그래프를 봤을때, 입력값의 양이 아무리 커져도 10이어도 100이어도 1000이어도 무조건 1이고 Gradient또한 0에 수렴하게 된다.
마찬가지로 입력값이 극한으로 작아져도 출력값은 무조건 0이 나오게되고, Gradient역시 0에 수렴함..
이런 문제가 있다보니, Hidden Layer가 Deep할 경우에 Backpropagation로 weight를 업데이트하는 DL 특성상, 뒤쪽 Gradient가 소실되는 문제가 발생하게 될 수 밖에 없다.
이러한 이유로 Sigmoid 함수는 0또는 1을 반환하는 이진분류에 주로 사용된다. (e.g. 긍정/부정, 정상/비정상 ...)
유사한 함수로 Tanh 함수가 있다.
간단하게 차이점은 입력값의 총 합이 Sigmoid와는 다르게 -1 ~ 1 구간이므로 평균이 0이 될 수 있다.(편향 X)
2. ReLU
대표적인 Hidden Layer의 Actication Fundion.

ReLU 함수는 입력값이 0보다 작을 때 출력은 0이고 0보다 크면 입력이 그대로 출력되는 함수이다.
따라서 0이상인 구간에서는 Gradient가 일정하고 수렴하는 구간이 없기 때문에 특정 값을 예측하거나 할때 사용하기 좋다.
대표적인 특징으로는 입력값이 바로 출력값으로 나오기 때문에 계산속도가 굉장히 빠르다고 한다.
(Sigmoid유형의 함수와 비교했을때 SGD 수렴속도가 6배..)
하지만 이 함수도 치명적인 단점이 있다.
입력(sum(weight))이 음수인 부분을 보면 모두 0임을 볼 수 있는데, 이 구간에서의 Gradient는 0이되어 정상적인 학습이 되지 않는다.
해결방안으로 ReLU 기반의 여러 함수들이 파생되었다. (e.g. LeakyReLU, PReLU ... )
3. Softmax
Multi Classification을 위한 함수

이 함수는 조금 응용단계의 Activation Fucntion이다.
여러개의 Target값을 Classification 해주는 함수인데 Sigmoid 함수처럼 0 ~ 1의 확률값을 반환해주는 함수이지만, 차이가 있다면 이진분류 / 멀티분류 이다.
위 그림을 간단하게 설명하면 강아지, 고양이, 거북이 세 동물중 하나를 예측한다고 했을때 각각 class의 확률값이 나오고, 그중 가장 큰 확률의 값이 최종적으로 선택(argmax)되는 모습을 나타낸 것이다.
흔한 예제를 들어보면,
대표적으로 누구나 해봤을 mnist 손글씨 분류 데이터셋에서
사진의 숫자가 0~9까지 총 10개의 class로 나누어져 있고 이 사진이 어떤 Class인지 예측하는 모델이 있다.
잘 생각해보면 Code Level 에서 보면 항상 볼 수 있었다.
y_pred = tf.nn.softmax(logits)아마 위와같은 코드를 (무조건)본적이 있을것이다..!!
'공부 > AI' 카테고리의 다른 글
| [DL] TypeError: TextEncodeInput must be Union[TextInputSequence, Tuple[InputSequence, InputSequence]] (0) | 2021.09.29 |
|---|---|
| [DL기초] batch_size, epoch, step 개념 그리고 iteration (1) | 2021.06.09 |
| [DL] 경사하강법(Gradient Descent) 직접 구현하기 (0) | 2021.06.04 |
| [DeepLearning] 딥러닝의 전체적인 흐름..? (0) | 2021.03.08 |


댓글